Semantic Shop
Stand: 19.2.2020
Einleitung
Produkte zu finden, die genau den Anforderungen entsprechen, die 1 Benutzer hat wird heutzutage immer schwieriger.
Möchte ein Benutzer ein Produkt finden, welches spezielle Anforderungen hat muss er sich zuerst umfangreich in anderen Quelle wie Reviews informieren. Das kostet Zeit. Wenn der Benutzer die eigentliche Suche in Shops bedient hat er meistens schon eine Entscheidung getroffen und gibt nur noch ganz kurze klare Suchbegriffe ein. Alles andere wäre auch nicht zielführend denn die Suchmaschine wird komplexere oder sogar natürlich-sprachliche Sucheingaben nicht verstehen. Denn auch größere Shops setzen immer noch auf die seit jahrzehnten übliche Keyword Suche: Taucht eine Sucheingabe nicht in irgendeiner Produktbeschreibungauf, kommen keine sinnvollen Ergebnisse.
Geben wir zum Beispiel etwas ganz simples wie „gute Waschmaschine“ bei Mediamarkt ein, so finden wir nur Audio-CDs. Der Nutzer muss seine Anforderung entweder gleich ganz weglassen, sich in Reviews oder ähnliches umschauen oder wird den Shop gleich ganz verlassen.
Unsere Technologie wird es dem Benutzer ermöglichen direkt und ohne langwieriges durchstöbern von Suchergebnissen und Details genau das Produkt zu finden was seinen Anforderungen entspricht. Aktuell muss der Nutzer versuchen dass ihn die Suchmaschine versteht, wir möchten eine Suchtechnologie bauen die den Nutzer versteht.
Datenbeschaffung
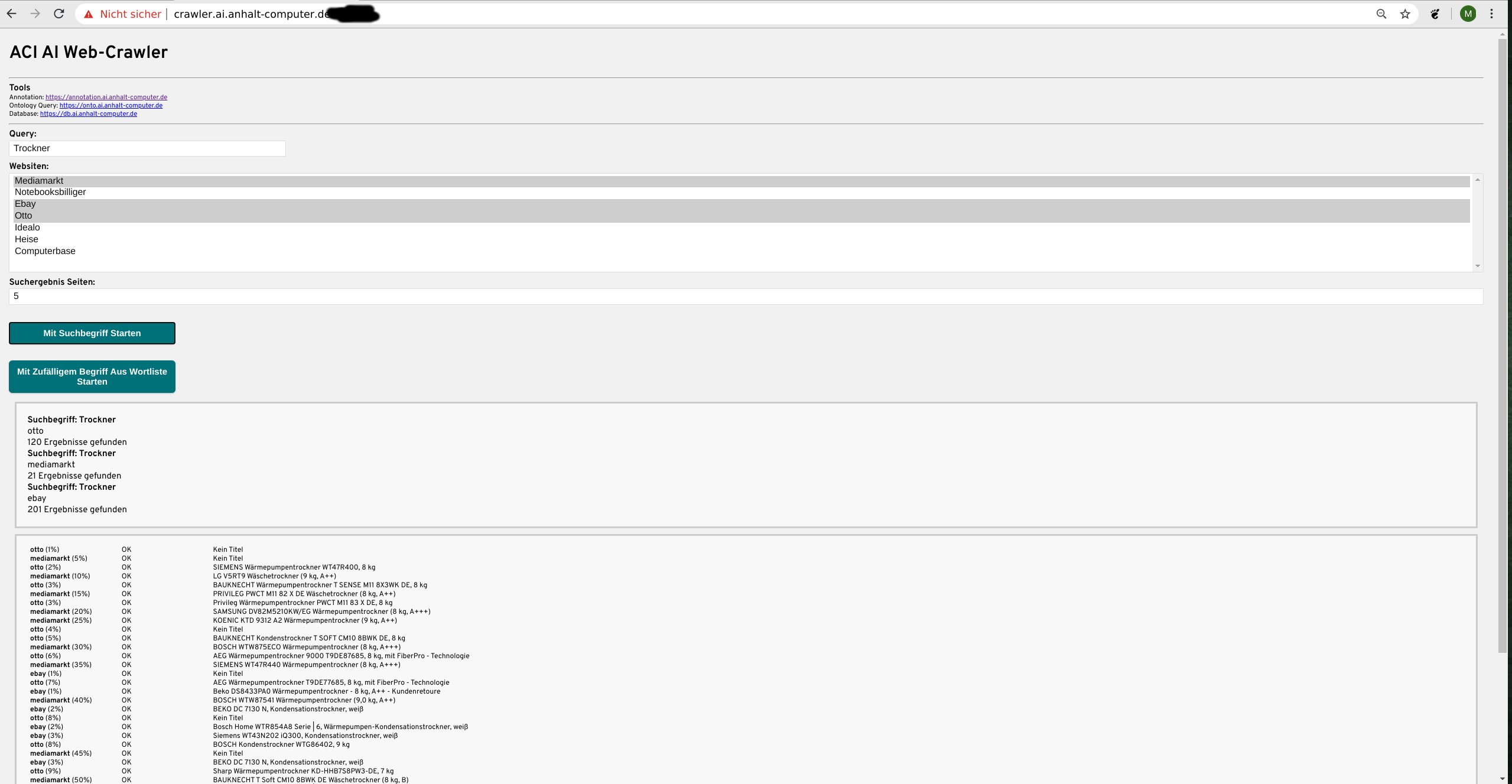
Die allerwichtigste Grundlage technisch ausgereifte Software zu entwickeln sind immer die Daten. Dazu haben wir einen eigenen Webcrawler entwickelt der Shops und deren Produkte durchsucht und sich dann alle Daten geordnet einverleibt die etwas über das Produkt aussagen. Der Crawler basiert auf Selenium (+ Chromedriver) damit kann er „physisch“ die Seiten aufrufen, Suchfelder bedienen, Unterseiten aufrufen usw.
Das ist nötig um die Restriktionen der Shops zu umgehen die sonst nach einigen wenigen Anfragen unseren Crawler (bzw. die IP) sperren würden. Aktuell ist es uns damit möglich die Informationen großer Shops wie Otto, Mediamarkt und Idealo ohne Restriktionen in kurzer Zeit anzueignen.
Aktuell haben wir etwa 50000 Produkte, knapp 1 Millionen Attribute und 200000 Reviews in unserem Datenbestand. Zu Beginn richten wir unser Augenmerk aber erstmal auf Weiße Ware (Sprich Waschmaschinen, Kühlschränke usw.)
Aktuelle Resultate
Der eigentliche Suchalgorithmus befindet sich noch am Start der Entwicklungsphase. Aber erste Ergebnisse zeigen, dass unser Konzept auf Basis unser Technologien (Siehe 4.) bereits sehr vielversprechend Funktioniert. Dem Benutzer ist es bereits jetzt möglich natürlich-sprachliche Sätze in das Suchfeld einzugeben und direkt zu sehen was genau denn die Suchmaschine verstanden hat.
Dadurch weiß der Benutzer ohne langes durchsuchen der Ergebnisse ob er tatsächlich genau verstanden worden ist. Wie in den Bildern zu sehen ist, wird die Sucheingabe direkt in die Attribute übersetzt, die der Nutzer vermeintlich bei seiner Waschmaschine haben möchte.
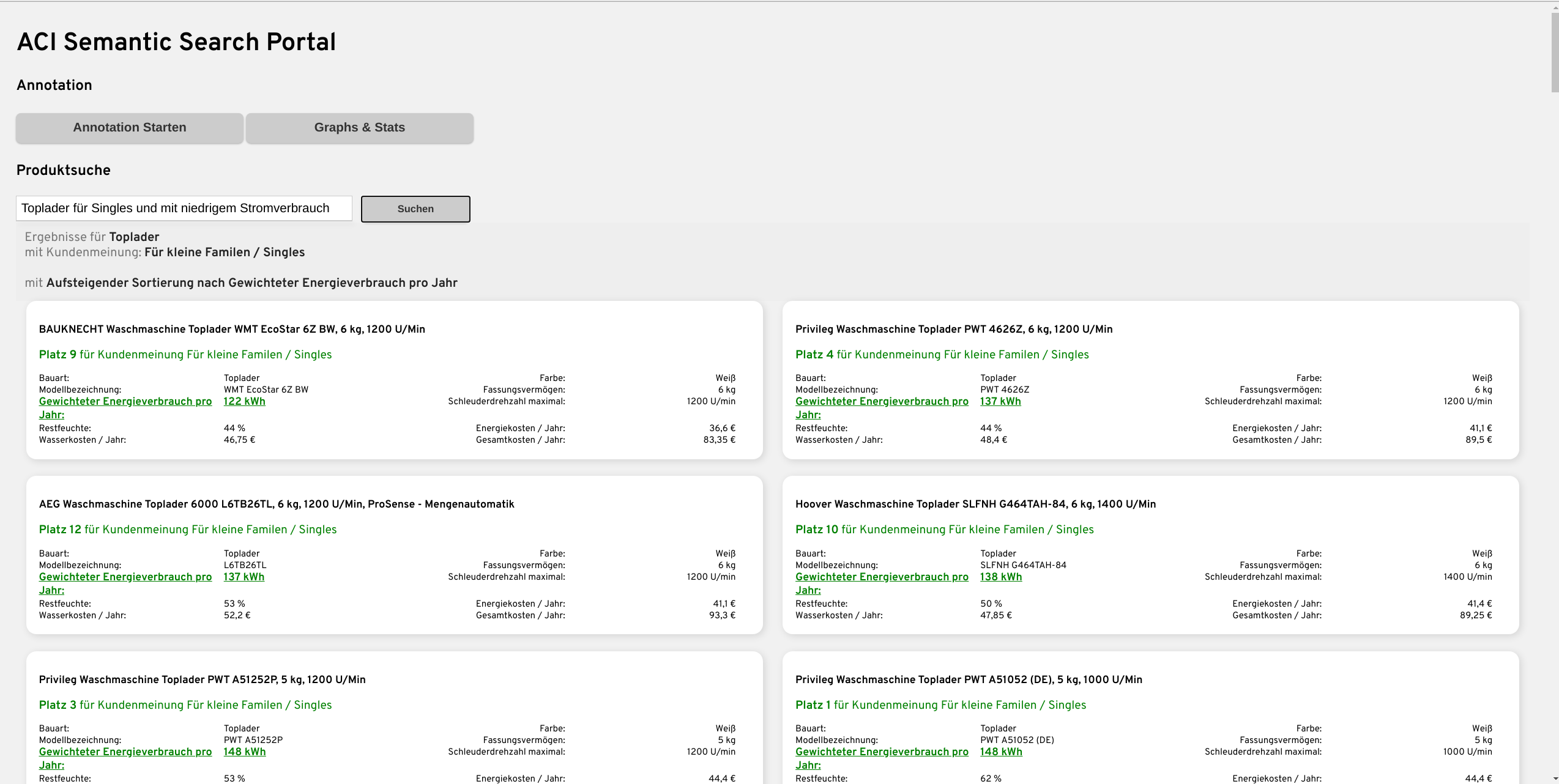
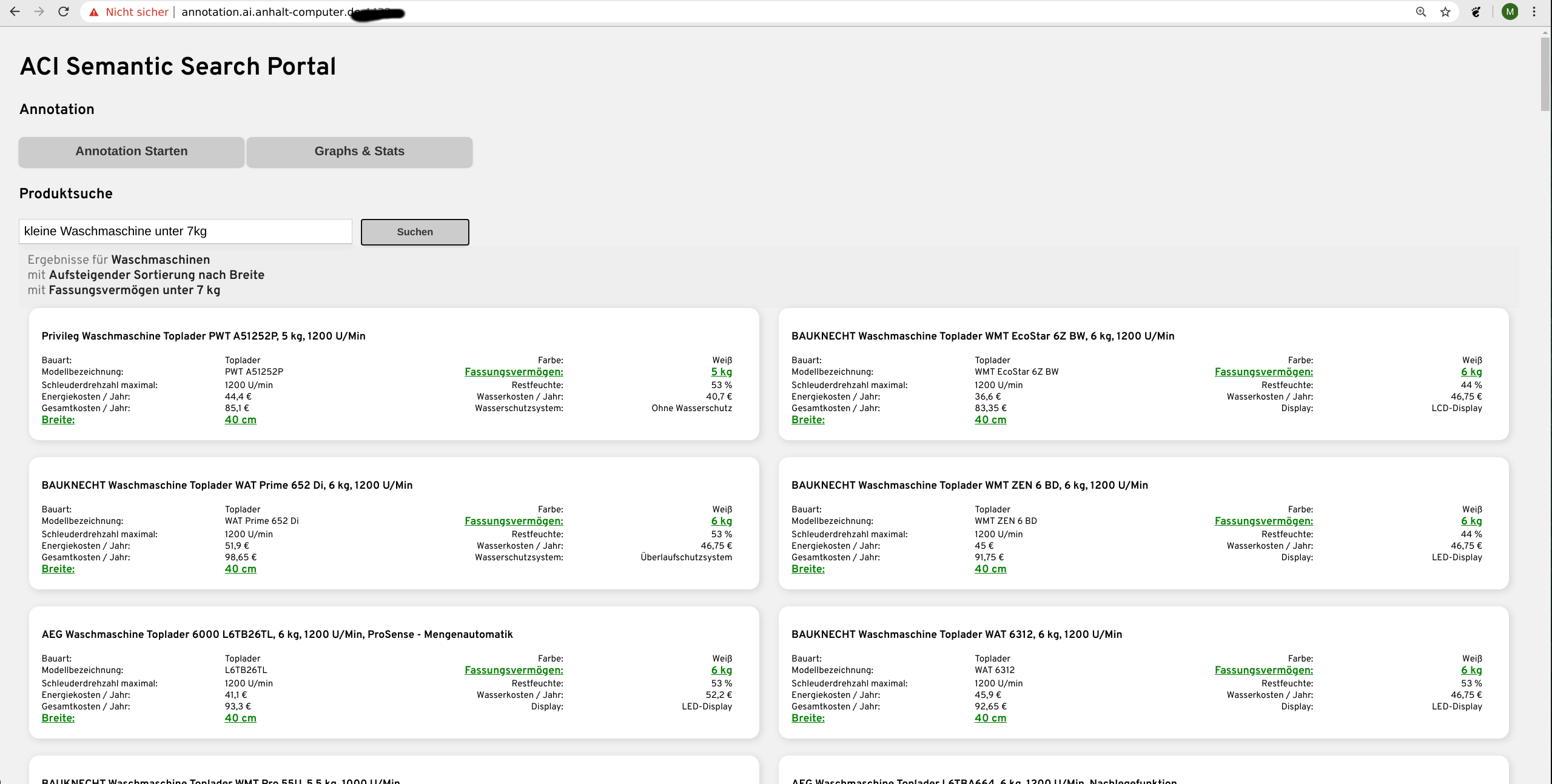
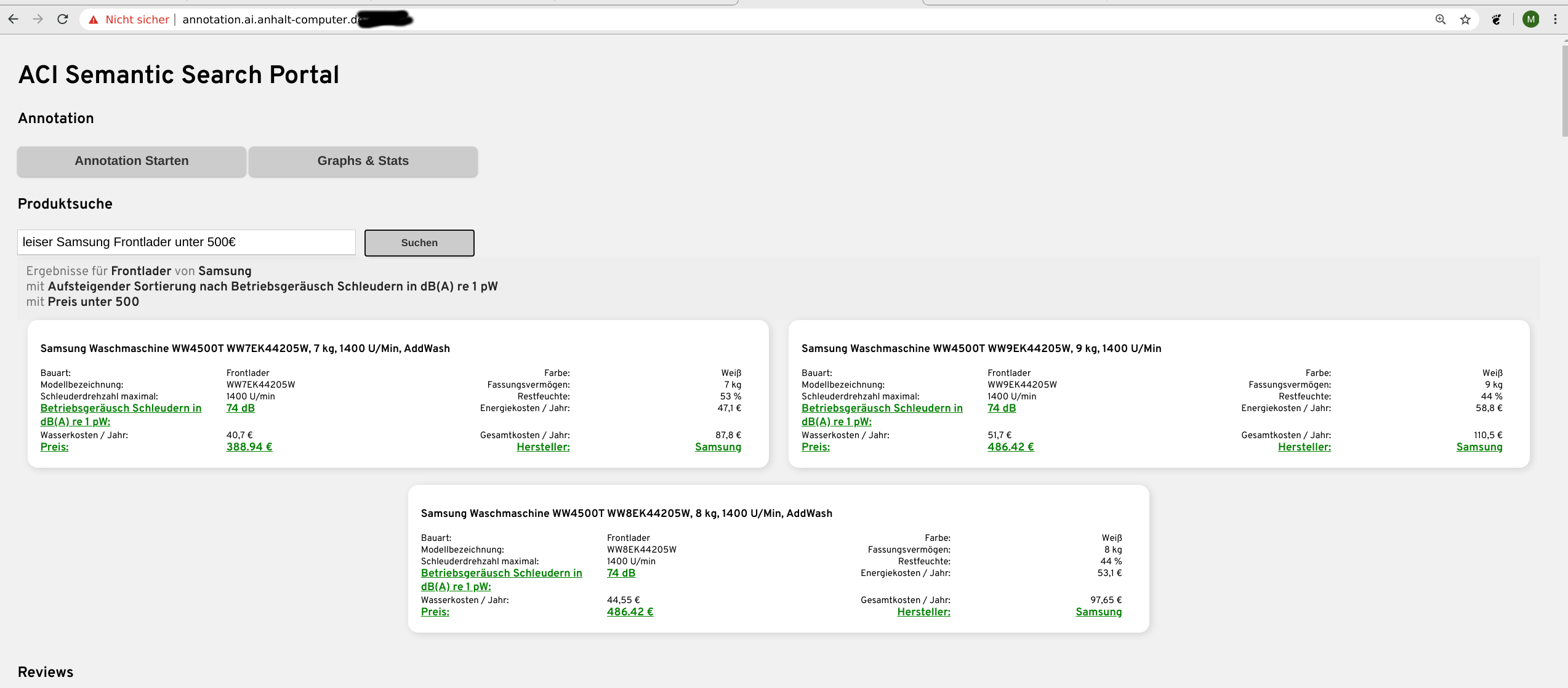
Alle Bilder zeigen unser selbstentwickeltes Web-Portal, wo wir einen Shop mit tausenden Produkten simulieren und alle Entwicklungen visuell mit allen Daten und Produkten testen können. Ein echten Shop aufzusetzen und ein Plugin zu entwickeln ist einer der nächsten Schritte.
Technologien
Die Suche besteht aus 3 Komponenten. Wir möchten versuchen den Einstieg in unser Produkt so einfach wie möglich zu gestalten.
Die erste Komponente alleine reicht bereits aus um einen Großteil der Benutzereingaben abzudecken. Dafür ist auch keine menschliche Vorarbeit nötig.
Die anderen beiden Komponenten sind für größere Shops gedacht, die das Budget haben menschliche Vorarbeit zu leisten. Die 1. Komponente funktioniert im Kern auf Basis von semantischer Ähnlichkeit. Das heißt alle Produktattribute und Beschreibungen werden in 300 Dimensionale Vektoren übersetzt.
Im Kern weiß dann das System dass beispielsweise bei einer Eingabe von „Kleine Waschmaschine“ nur das Attribut „Breite“ (oder Höhe) gemeint sein kann weil es von allen Attributen die größte Semantische Ähnlichkeit zu „Klein“ besitzt.
Bidirectional Transformers
Das ganze funktioniert mithilfe einer State of the art Technologie namens BERT (Bidirectional Encoder Representations from Transformers).
Dazu trainieren wir automatisch mithilfe eines Textkorpuses mit mehreren Millionen Sätzen (aus den Daten unseres Crawlers) ein Modell, dass bestmöglich für unsere Aufgabe optimiert ist. Damit kann die 1. Komponente der Suche bereits ein riesiges Feld von Eingaben abdecken.
Beispielsweise kann eine Eingabe wie „Waschmaschine mit einfacher Bedienung“ durch unser Modell zugeordnet werden zum Attribut „Touch Display“. Den das trainierte Modell weiß nun, dass einfache Bedienung maßgeblich vom Bildschirm beeinflusst wird weil es im großen Textkorpus oft in diesem Zusammenhang beschrieben worden ist.
Auch die 2. Komponente funktioniert mithilfe unseres BERT Modells. Wir können damit Reviews klassifizieren. Wir möchten zum Beispiel wissen, welche Waschmaschine ist am besten geeignet für Große Familien, so können wir dies Teilautomatisiert anhand der Reviews herausfinden.
Dadurch kann die Suche auch für subjektive Suchanfragen ein passendes Produkt liefern und ausgeben in wie weit andere Kunden finden dass die Waschmaschine für eine „Große Familie“ geeignet ist.
Weiterhin haben wir dadurch riesige Mengen an Sätzen die alle die Aussage „Für Große Familie geeignet“ repräsentieren. Auch das hilft uns bei der Suche die korrekte Zuordnung zwischen Sucheingabe und Attribut zu vollführen. Denn das System weiß nun das „Waschmaschine für 4 Personen“ semantisch die gleiche Suchanfrage ist wie „Waschmaschine für Große Familie“
NLP
Um die Suchanfrage zu verstehen müssen wir sie in Ihre linguistischen Einzelteile zerlegen. Wir müssen verstehen welche Beziehung haben die Wörter zu einander, sind e s Substantive, Adjektive oder Verben.
Dazu baut unser Algorithmus auf spaCy auf. Wir können auch lange, natürlich-sprachliche Sätze in seine einzelnen Bestandteile (Noun Chunks) zerlegen und auch spezielle Sucheingaben wie „kleiner als“, „unter“, „über“ usw. verarbeiten.
Wir wissen auch wann ein Kunde etwas sucht was sich durch absteigend/aufsteigend sortierte Ausgabe der Produkte abbilden lässt. „leise“ (Kleinste Lautstärke“), „klein“, „breit“ und so Weiter.
Ontologien
Die dritte und umfangreichste Komponente funktioniert auf Basis von Wissen abgespeichert in Ontologien. Um den kommerziellen Erfolg unseres Systems zu gewährleisten ist diese, wie auch die 2. Komponente optional. Denn die Erstellung von Ontologien ist mit hohem Aufwand verbunden. Einen Aufwand den nur größere Shop-Betreiber werden leisten wollen.
Ontologien speichern Fakten und Zusammenhänge zwischen Attributen. Am einfachen beispiel von „Waschmaschine für Singles“ heißt das in dem Fall: Eine Waschmaschine ist für Singles geeignet dann wenn sie „Günstig“ (Definiert in der Ontologie zb. unter 300€) ist und eine „kleine Trommel“ (Definiert in Ontologie unter 6kg Volumen) hat.
Durch die Definition dieser Zusammenhänge können wir automatisiert mithilfe eines Semantic Reasoners neue Aussagen ableiten und damit neues Wissen generieren. Dadurch versuchen wir auch ultra komplexe Suchanfragen verarbeiten bei denen die ersten beiden Komponenten versagen.
Gemeint sind komplexe Suchanfragen wie von einem Nutzer der eine Waschmaschine für seine Oma sucht, die ein sehr kleines Bad hat. Was ist dem Nutzer in dem Fall wichtig? Solche Zusammenhänge lassen sich mit dem in der Ontologie gespeicherten Wissen abbilden und dann herunterbrechen auf die physischen Attribute die hinter jedem Produkt stehen.
